Hadoop and Hive integration with OPC UA
24.06.2014
The big data seems to be the talk of the town at the moment. Enterprises in various fields are utilizing the concept, or at least say they do. Be that as it may, most today’s largest web companies trace their success or business model to deriving value from this ‘big data’. Examples of these well-known companies include e.g. Facebook, Amazon, Google and Netflix. (To appreciate the power of big data, think only of Amazon’s humble beginnings as an online bookstore back in 1994, which, among other things, is discussed here.) But precisely due to the huge amount of talk and hype, it is ever more difficult to clearly see what big data really is about. This blog post tries to shed some light on the issue, and also demonstrates with a simple demo case the possibilities of OPC UA and big data integration.
According to Gartner, big data means revolution in the collection and use of data, namely in the dimensions of volume, velocity and variability. Despite the handy alliteration, these terms describe core aspects of big data quite well. Concisely put, volume stands for the huge increase in the amount of raw data. This has, among other things, forced development of new ways of going through that data. Velocity states that also the rate at which data is generated is greatly increased, creating bandwidth and storage issues to be solved. Variability (perhaps the least self-evident here) states that the data formats change in ever more faster cycles. This makes it hard to build static data models of which most (relational) database implementations depend upon. Traditionally the data models have driven the application development, which simply is not (and hasn’t been for some time) feasible anymore.
In regards to automation industry, big data mostly means ever-increasing amounts of sensor data from the production process. Additionally, with the rise of MES (Manufacturing Execution Systems) and various ERP (Enterprise Resource Planning) solutions, data is bound to increase also in the upper reaches of plant management. However, integrating and unifying all this data is usually the most difficult part. Big data platforms (following shortly) promise easy-to-maintain and flexible data hosting environment, which ease the creation of ‘master records’ covering the whole plant infrastructure.
Hadoop explained
So, what makes these gigantic leaps in data utilization possible? One of the main building blocks of big data is Apache’s Hadoop. It is essentially a distributed file system built to work concurrently on top of commodity hardware. Many useful tools of (big) data analysis integrate and use the Hadoop file system (HDFS) as their backbone due to its distributed and extendable nature. Figure below illustrates a generic use case of the Hadoop platform to build analytical functions.
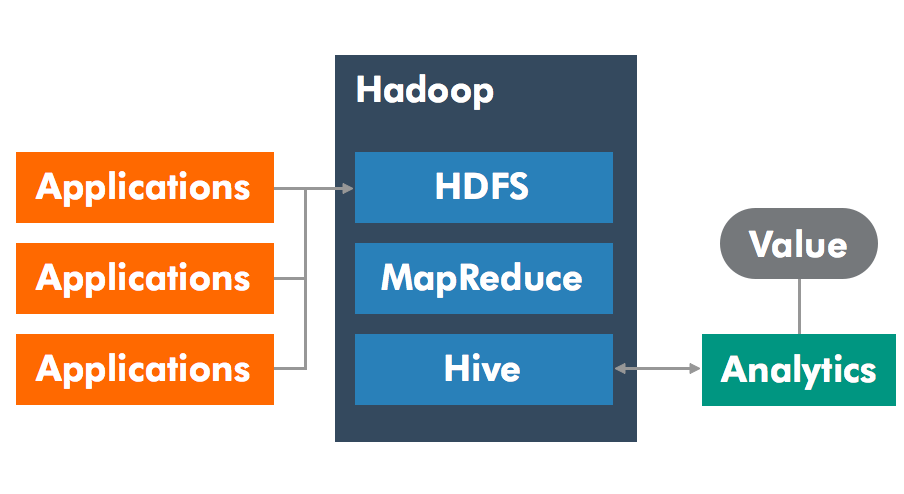
Hadoop comes with MapReduce, a computing paradigm making it easy to write distributable and parallelizable analysis jobs. (Easy being somewhat in quotation marks here.) The idea is to divide the problem into Map and Reduce functions, which can be parallelized separately. In general terms, Map function takes a set of key-value pairs and calculates intermediate results from them, generating another set of key-value pairs. This operation is automatically parallelized to the Hadoop cluster. The Reduce function then takes all the grouped intermediate results and calculates some aggregate values based on them, again in parallel. The user has to write these Map and Reduce functions, as they depend on the problem being solved, but the issues with parallelization, faulty hardware and communication are taken care by the MapReduce library.
Hive, another mainstream tool, is essentially a distributed data warehouse, which can be accessed using SQL syntax. Any SQL query or insert is converted automatically into several Map and Reduce jobs, distributed within the configured cluster of machines. Both the results and data are thus stored within the HDFS in a distributed manner. Hive is best suited to running batch operations on data.
HBase is a non-relational database modelled after Google’s Bigtable, working on top of HDFS. In most cases the data from Hive and HBase can be easily exported and imported into each other. HBase, however, is more suitable when real-time processing and results are needed.
HUE (Hadoop User Experience) web application can be used to access most analysis tools available at the moment. The application includes query tools, data browsers and the ability to build custom web UIs with Hue’s Search app. The search feature is built on top of Apache’s Solr search platform.
One point of this blog post is to show how the tools developed by web giants can be used without investing enormously into data centers/clusters and without employing hordes of top-notch, hotshot data scientists. (I.e. that the concepts are not scary, many-legged monsters eating up your offspring.) Still, to reap the benefits of the architecture, more than single node (i.e. operating system running on some actual hardware) is recommended.
Next, a simple demo case is introduced showing the viability of OPC UA and big data integration.
Streaming OPC UA data to Hadoop
For demo (and blog) purposes, we streamed our Raspberry PI Weather Station data into Apache Hadoop and Hive, the last of which was used for analysis. More precisely, in the first step temperature data from OPC UA server in Raspberry PI was inserted into MySQL database using the Prosys OPC UA Historian (prototype). In the second step, MySQL database binary logs were streamed into HDFS with Tungsten Replicator (a freely available integration tool). The replicator produced csv-files from the binary logs. Lastly, these csv-files within HDFS were automatically imported into Hive as external tables. Whole setup consisted of two virtual machines running within the same server. The end result was OPC UA data available at Hadoop file system and Hive! A schematic view of the setup is seen below.
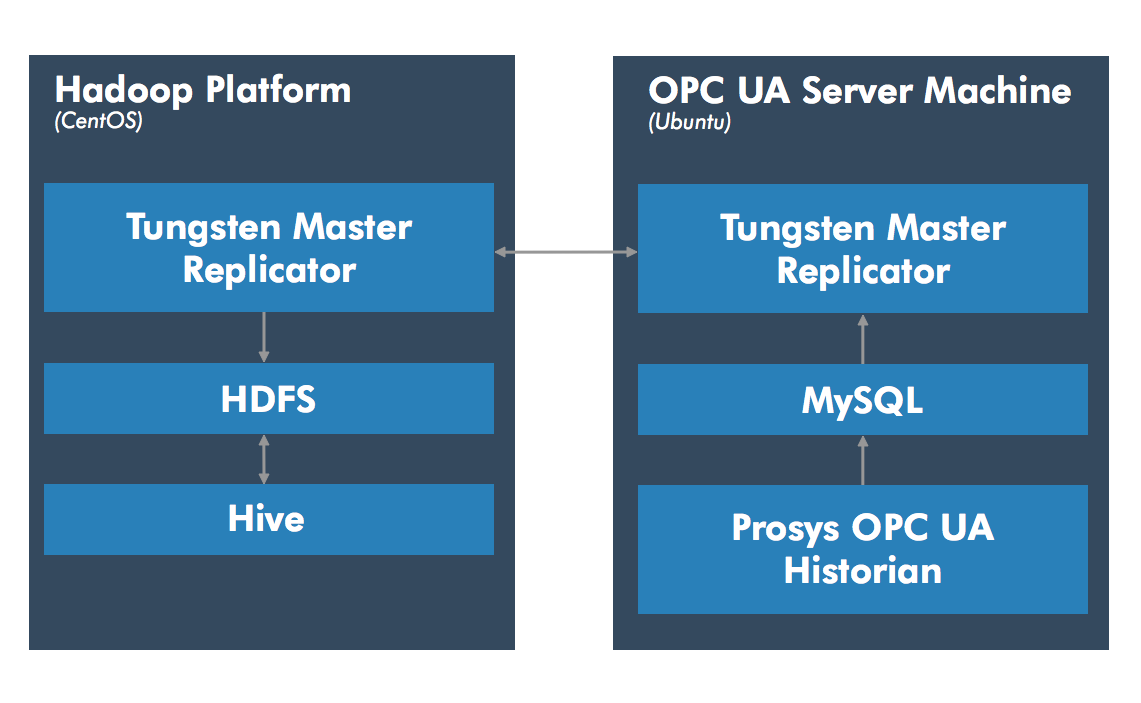
First of all, the Cloudera Quickstart Virtual Machine was used as a fully functional, out-of-the-box Hadoop solution (available for VMWare, VirtualBox and KVM platforms). It contains the needed big data tools with a central (web-based) management panel. It is freely available to download and is built on top of CentOS, a popular linux distribution.
Another virtual machine (with Ubuntu OS) running the prototype Prosys OPC UA Historian and MySQL community edition was used. The Prosys Historian connected to the Raspberry PI Weather Station through OPC TCP address. Finally, Tungsten Replicator handling the data transfer between MySQL and HDFS was installed to both virtual machines.
Setting up the system
Next, we look more closely in how to create a similar system as is described above. From now on, the master OPC UA machine running the MySQL is identified as host1 and the Cloudera Hadoop platform as host2. On the Tungsten Replicator viewpoint, host1 is master and host2 slave machine. Modify /etc/hosts file in both virtual machines to link IP-addresses of the host machines to host1 and host2.
Prerequisites
First of all, both hosts need to be able to SSH each other with the tungsten user. Create user with username ‘tungsten’ and password ‘password’. Key commands to create user in linux OS are:
sudo adduser tungstenThen add to file
/etc/sudoersa line
tungsten ALL=(ALL) ALLto give tungsten user necessary super user rights.
To give Tungsten Replicator access to MySQL in the host1, write in mysql command line:
CREATE USER tungsten@'%' IDENTIFIED BY 'password';
GRANT ALL ON *.* TO tungsten@'%' WITH GRANT OPTION;Then make sure that the MySQL configuration file my.cnf has these lines:
#bind-address = 127.0.0.1
server-id = 1
open_files_limit = 65535
log-bin = mysql-bin
sync_binlog = 1
max_allowed_packet = 52m
default-storage-engine = InnoDB
innodb_flush_log_at_trx_commit = 2Above procedures are the key points in setting up the environment. Detailed instructions on the whole preliminary process are found here.
Tungsten Replicator
Then, download the latest Tungsten Replicator 3.0. Unpack it by running
tar xzf tungsten-replicator-3.0-xx.tar.gzand
cd tungsten-replicator-3.0-xxTo install on the Hadoop platform (host2), write:
./tools/tpm install alpha \
--batch-enabled=true \
--batch-load-language=js \
--batch-load-template=hadoop \
--datasource-type=file \
--install-directory=/opt/continuent \
--java-file-encoding=UTF8 \
--java-user-timezone=GMT \
--master=host1 \
--members=host2 \
'--property=replicator.datasource.applier.csv.fieldSeparator=\\u0001' \
--property=replicator.datasource.applier.csv.useQuotes=false \
--property=replicator.stage.q-to-dbms.blockCommitInterval=1s \
--property=replicator.stage.q-to-dbms.blockCommitRowCount=1000 \
--replication-password=password \
--replication-user=tungsten \
--skip-validation-check=DatasourceDBPort \
--skip-validation-check=DirectDatasourceDBPort \
--skip-validation-check=HostsFileCheck \
--skip-validation-check=InstallerMasterSlaveCheck \
--skip-validation-check=ReplicationServicePipelines \
--rmi-port=25550 \
--start-and-report=trueInstallation doesn’t go through if any of the prerequisites fail. In that case fix the warnings, delete all the created files, and unpack the .tar.gz again. The Tungsten Replicator is by default installed into:
/opt/continuent/tungsten/tungsten-replicator/binNext, create a data schema for the Hive. This can be done with a provided ddlscan utility. Write in the above folder:
./ddlscan -user tungsten -url 'jdbc:mysql://host1:3306/test' -pass password -template ddl-mysql-hive-0.10-staging.vm -db test > schema-staging.sqlto create the schema initialization commands. Modify the database name to the correct one (i.e. other than test). Also check that the Hadoop path within the schema-staging.sql is correct. It should be something in the lines of
/user/tungsten/staging/alpha/...If the paths are correct, apply the schema to Hive using cat:
cat hive | schema-staging.sqlTo install the replicator on the MySQL master (host1), download and unpack it as before, and run:
./tools/tpm install alpha
–install-directory=/opt/continuent
–master=host1
–members=host1
–java-file-encoding=UTF8
–java-user-timezone=GMT
–mysql-enable-enumtostring=true
–mysql-enable-settostring=true
–mysql-use-bytes-for-string=false
–svc-extractor-filters=colnames,pkey
–property=replicator.filter.pkey.addColumnsToDeletes=true
–property=replicator.filter.pkey.addPkeyToInserts=true
–replication-password=password
–replication-user=tungsten
–skip-validation-check=HostsFileCheck
–skip-validation-check=ReplicationServicePipelines
–start-and-report=true
Everything should now be up and running. To check the local installation, run the following command in bin-folder:
./trepctl status It shows the state and properties of the replicator. Another way to check the installations (even remote ones, just replace host1 with the appropriate hostname) is to write:
./trepctl -host host1 statusThe replicator can be started and stopped with:
./replicator startand
./replicator stopcommands, respectively.
If you run into trouble, the whole process of setting up Tungsten Replicator with Hadoop is described in great detail here.
I had initially problems with permissions to writing to the Hadoop file system as Tungsten user, and as a solution ran the replicator in host2 using cloudera user (i.e. open terminal as the cloudera user). Despite this, the replicator had access to the MySQL master (host1) without any problems.
Now, if everything went smoothly, you should have two replicators running and streaming binary logs into the HDFS and Hive. (To see the data show up in Hive, insert something into the master MySQL database.) Hive can be used either from command line (type hive) or from the Hue web application. Use whichever you like to create a select query and see the results printed on screen. Voilà, you have a working big data platform with automated input data stream!
Still, to use the platform effectively, several data selection and analysis queries need to be formulated. In the demo case, I chose to do simple value cleaning of the temperature data, along with showing the correlation between external and internal temperature sensors. Web application has the option to create simple graphs from the results (see below) and also allows to choose the database and tables using GUI.
The results below show temperature values within few hour timespan. The select query filters some clear outliers away, as the sensor jumps intermittently either to very small or large values.
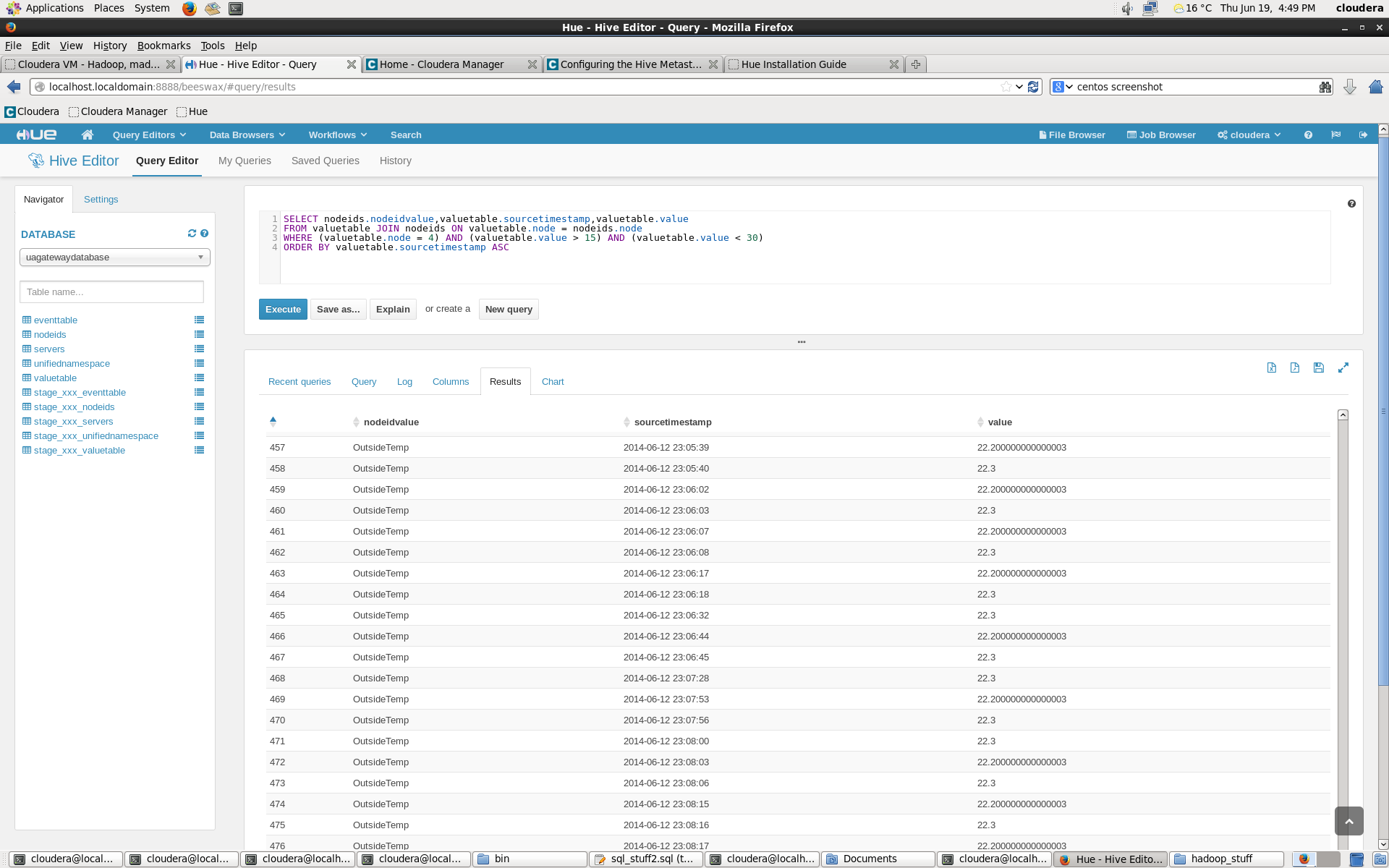
The built-in graph tool can also be used to show the values. Below are results from a query with the filtering.

To calculate correlation between two temperature time series, a built-in Hive function is used. The correlation shows non-existent connection between inside and outside temperatures of the PI Weather Station, as it should.
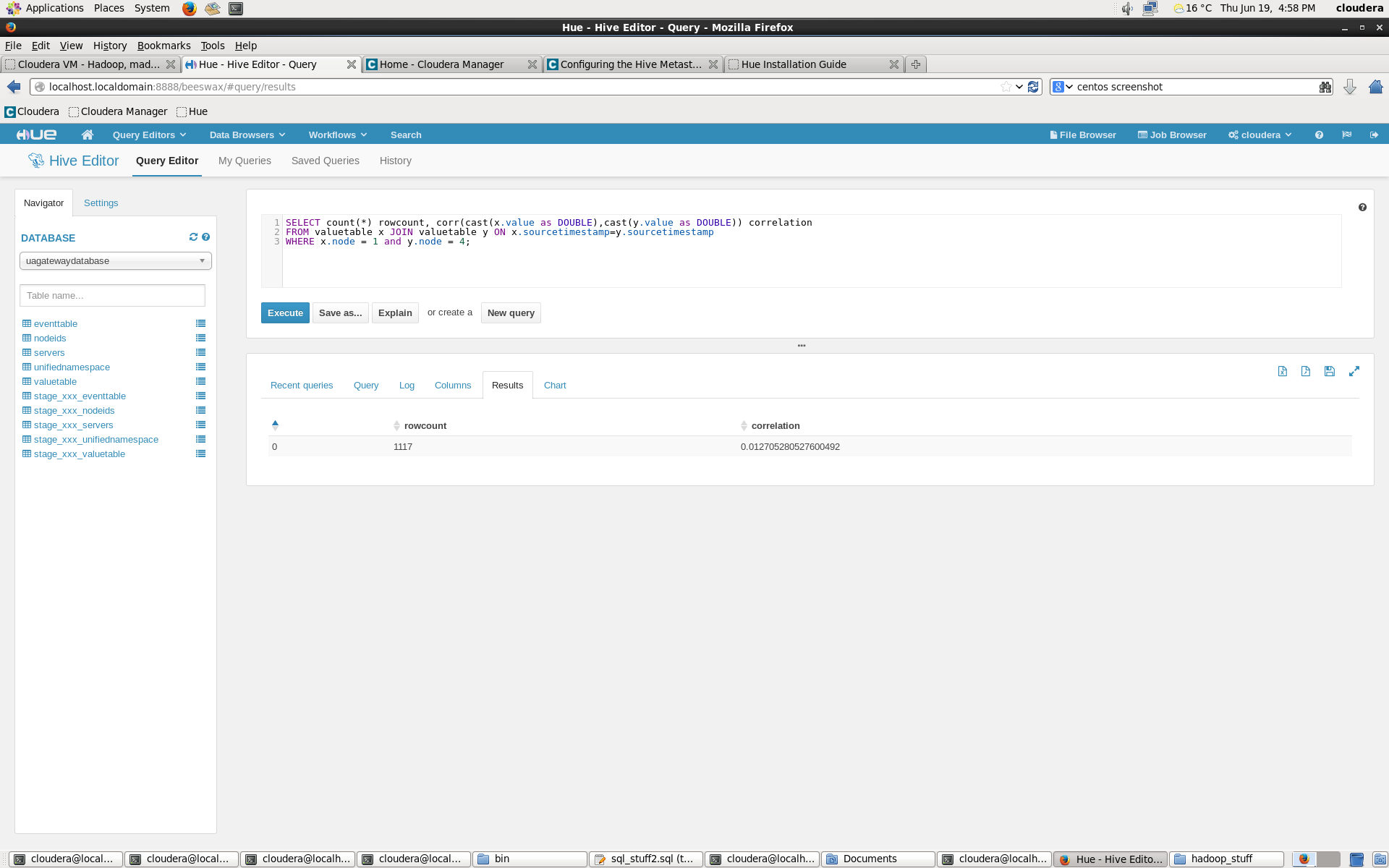
If Hive gives error messages about Java Heap size while running the queries or inserts, I suggest to increasing the Java Heap sizes of Hive and Yarn services from the management panel. (Yarn handles the MapReduce jobs.)
As a further improvement, Solr (and Hue’s Search) could be used to create interactive user experience with minimal effort. This might come about in subsequent posts as the search tool is expanded greatly in the recent Hue 3.6. release. Also, Hadoop ecosystem holds many more tools not mentioned here (e.g. Pig, Sqoop, Oozie, Flume, etc.) which, however, are not discussed further in this already lengthy post.
Conclusion
All in all, this post has demonstrated the relative ease of using big data platforms, or at least the Cloudera one. For a case of this magnitude, however, the solution is by no means practical. The main advantage of using Hadoop type storage (along with the rest of the ecosystem) is its wide availability and flexibility, which encourages to build light-weight applications on top of it. Thus the quickly changing source data schema need not dictate the applications using it. This effectively transforms the traditional schema-on-write to schema-on-read, where analytic functions can be built on pre-existent data as the need arises.
As it is, many companies have major problems with splintered data storages and silos in separate locations which do not communicate with each other. Big data platforms make it easier to gather up the messy data streams from multiple sources, eventually allowing insight into the processes and patterns of the company. Nevertheless, any concrete goal or question (formulated prior to building the big data solution) is bound to steer and streamline the solution to the right direction, ensuring that value is truly generated from the analysis.

Jukka Asikainen
Lead Software Engineer
Email: jukka.asikainen@prosysopc.com
Expertise and responsibility areas: OPC & OPC UA product development and project work
Tags: Big Data, OPC UA, Database
comments powered by DisqusAbout Prosys OPC Ltd
Prosys OPC is a leading provider of professional OPC software and services with over 20 years of experience in the field. OPC and OPC UA (Unified Architecture) are communications standards used especially by industrial and high-tech companies.
Newest blog posts
Why Do Standards Matter in Smart Manufacturing?
The blog post discusses the importance of standards in smart manufacturing, envisioning a future where auto-configurable systems in manufacturing rely on standardized data formats for seamless integration and reduced costs, with a focus on the OPC UA standard family as a key enabler.
OPC UA PubSub to Cloud via MQTT
Detailed overview of the demo presented at the OPC Foundation booth
SimServer How To #3: Simulate data changes on a server using an OPC UA client
A two-part step-by-step tutorial on how to write data changes on an OPC UA server using an OPC UA client.